Playbook
Playbook covers our best practices and gives you the best insight how we deliver successfull long-term software projects.
LiteOps
When we launched NECOLT more than 10 years ago we had no previous real-world software development experience. We were lucky enough not to inherit the broken methods used in the industry. Instead, we tried to embrace emerging methodologies and combine them with our own methods. Later in 2009, DevOps emerged. Surprisingly, DevOps evangelists talked about problems that had never existed in our team. This was a clear sign that our methodology provided a great solution for well-known DevOps related problems for smaller and mid-size teams. We call this methodology LiteOps.
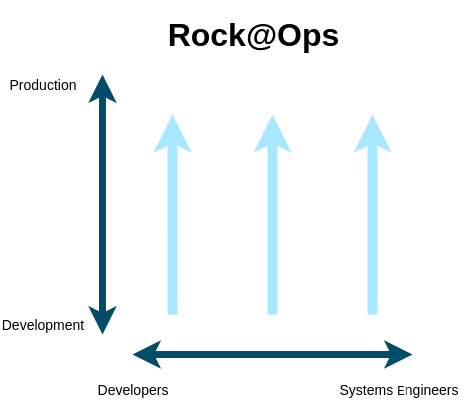
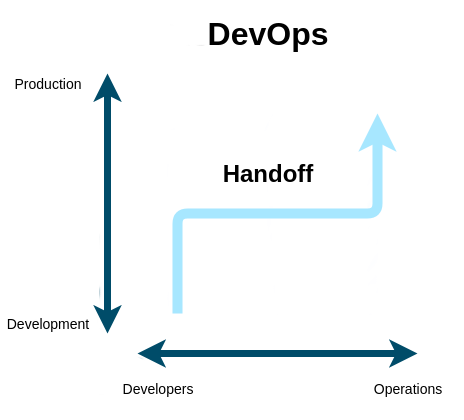
The benefits of this methodology are manifold:
- Huge savings - we develop and maintain large long-term projects at a fraction of the resources needed when using alternative approaches.
- Faster delivery - fast cycles in the entire software process enable us to ship multiple times a day during the entire life-cycle of the project.
- Higher quality - users and businesses appreciate the quality of the increments we ship every day.
- Low incidents - very rare production incidents lead to huge savings, a very stable product, and satisfaction all round.
- Easy scaling - LiteOps allows us to scale teams easily as it doesn’t rely on rare cross-disciplined experts.
We use LiteOps methodology for all our projects. It works well for a wide range of projects from smaller niche jobs to bigger 50 000 dev hours projects with millions of users. Our experience with a wide range of successful projects has helped us to shape LiteOps methodology and define its main practices. You need to follow this methodology thoroughly because using only part of the methodology will only get you part of the results, or even worse - no improvement at all. Also, this methodology will not deliver results without coding and quality assurance practices, such as our Software Design, Coding and Testing practices. As our methodology doesn’t rely on experts that are highly skilled in both software development and systems engineering or other combinations, it’s perfectly accessible to the majority of teams consisting of Developers, Systems Engineers, Testers and other roles.
LiteOps is built around a single core principle:
There is no dedicated operations role: instead every role in the team performs production operations for everything that role built.
For example, Developers build software and solve issues caused by their code in production. They write code, write and run automated tests, improve code according to team feedback, deploy to production, receive performance notifications and bug reports, solve code performance issues, fix bugs and do anything else that is needed to deliver their developed features to end users. They truly perform all operations for the applications they build. Moreover, every role tries to empower other roles to perform their operations themselves instead of directly performing operations for the things that they didn’t build. For example, Systems Engineers empower Developers to perform application operations by building and operating infrastructures that Developers clearly understand and can easily build applications on top of. So, Systems Engineers don’t perform application operations, they merely ensure that the infrastructure is the best that it can be so that Developers can conveniently perform operations for their produced code. Sometimes Systems Engineers advise Developers when they need help in systems engineering, but the largest part of the Systems Engineers efforts are dedicated to empowering Developers to perform application operations themselves. Other roles, such as DBAs or testers participate in the process in similar ways.
You can see this methodology from a different angle too. LiteOps reduces handoffs to the minimum. This means that every role contributes and participates to the very end of the delivery pipeline for everything that role built, instead of the classical workflow when one role hands off (in reality just throws over the wall) to another role, which causes all kind of problems. This completely changes the mindset of everyone involved. Every role starts to deliver increments that actually work in production instead of throwing over the wall half-baked solutions to other roles (as in the classical Developers to Operations handoff). Such clear responsibility for each role gives LiteOps a huge advantage over other approaches such as DevOps.
While the core principle is simple, LiteOps consists of a lot of smaller elements. Unlike DevOps, it’s not too complicated to correctly implement LiteOps as it’s a set of practices that work together very well and bring outstanding results. The majority of these practices cover Developers and Systems Engineers, but most of these practices apply to other roles too. If you feel like giving this methodology a try in your team, feel free to share your experience with the author of LiteOps - Saulius Grigaitis.
Simplicity
Simple things work better. Complex things tend to break more often than simple ones. Infrastructure follows this rule. That’s why we prefer lightweight, simple and reliable infrastructures built using simple and reliable components. There is another very important aspect to such simple infrastructures - they encourage Developers to investigate production environment issues. Developers are happy to fix issues in production provided they feel comfortable with the infrastructure and understand it well. The simplest possible infrastructure is usually the infrastructure that Developers understand most.
Some Systems Engineers believe that they help Developers by automating complex environments that Developers don’t understand. Well, this helps in the short-term, but it makes things worse in the long-term because Developers build software on top of environments that they don’t understand. It’s much better to use simple environments that Developers clearly understand instead of automated complex environment setups that Developers barely understand. Ideally, the environment should be both automated and clear for Developers.
Reliability
The LiteOps methodology will work only if the infrastructure is reliable. Developers will start to ignore production issues if there have been a lot of incidents when the code was working, and the issue was in the infrastructure. You will start to hear Developers saying “Ah… something is wrong with the infrastructure. It works on my machine!”. This is exactly what we want to avoid by creating reliable infrastructures.
We use multiple methods and strategies to build reliable infrastructures. For example, we tend to avoid 3rd party services; instead, we try to build infrastructures using widely used battle tested open source components. There are multiple benefits to this approach. First, the team better understands how that particular technology works under the hood compared to a black-box 3rd party service. This helps us to build better and more stable applications on top of this technology. Second, we have full control of the deployed components. If something goes wrong, the Systems Engineer can fix it without the kinds of delays that are common to 3rd party services.
System Engineers need to achieve infrastructures that are reliable enough to ensure that only a very small amount of production issues are infrastructure issues. Only then will Developers feel that the code they have produced is the main contributor to product reliability. This totally shifts Developers’ mindsets. Developers start to care about their code in production. They start to investigate and fix the production issues that have been caused by their changes. They start to make greater efforts to prevent production issues. That’s the goal!
Responsibility
LiteOps defines very clear responsibility. Systems Engineers are responsible for the infrastructure and its operations, they are not responsible for application code and its operations, but they help Developers when there is a need, especially when application issues are related to an infrastructure. Developers are responsible for application issues in production. Developers are not responsible for an infrastructure itself, but they collaborate with Systems Engineers on application issues that relate to that infrastructure. This clear separation of responsibility allows issues to be solved by the people who know these areas best. For example, if an application bug is introduced with the latest deployment, then the Developer who introduced the bug fixes that production issue. If there is an infrastructure issue, then the Systems Engineer is usually the best person to fix it. This also brings mental benefits - people don’t need to solve issues caused by others.
Each role is responsible for their individual outcomes. It may look as though each party has full ownership, which can lead to separation and less collaboration. Actually, the opposite is true. Developers are responsible for their code in production, so they consult more and more with the Systems Engineers because Systems Engineers usually have more operations experience and more knowledge of how to make things work better in production. Systems Engineers need to develop the best infrastructure, and application knowledge is part of infrastructure development, so they in turn often consult with Developers. So, this clear responsibility really encourages collaboration between Developers and Systems Engineers because this collaboration is crucial for each party to succeed in their jobs.
Transparency
We found that one of the most common root causes of software process issues is a lack of transparency. The more transparency there is, the better the decisions are that the team members make. That’s why we try to make everything as transparent as possible to avoid potential issues. For example, let’s imagine the common situation where a Product Owner is pushing new features to every Sprint Plan and doesn’t leave enough room for Developers to improve the already shipped code of the growing system. Everything looks good from the Product Owner’s point of view as the full focus is on the new features for users. Users do not experience any noticeable issues with the already shipped features so why spend time on them? Developers begin to receive early monitoring notifications of degraded performance or other issues this growing system is experiencing. Developers then inform the Product Owner, but the Product Owner is normally under a lot of pressure to ship features, so anything that doesn’t halt everything simply receives far too little attention. Eventually, the system starts to experience production issues and suddenly everyone becomes frustrated. This can lead to heated confrontations between the Product Owner and Developers. The Product Owner thinks that the Developers are now failing to ship quality code, while Developers feel frustrated as they have warned the Product Owner on numerous occasions about it. This is definitely a situation everyone wants to avoid.
The root cause of the situation above is a lack of transparency. The Product Owner simply doesn’t know how important the necessary improvements the Developers are talking about are. Even more importantly, the Product Owner doesn’t understand that the situation is progressively getting worse over time. It’s possible to easily solve this by being more transparent with the Product Owner. The first step for Developers and Systems Engineers is to create tickets at the top of the backlog to investigate degraded performance. If that doesn’t attract the Product Owner’s attention, the next step is to add the Product Owner to the list of receivers of monitoring system notifications. This way the Product Owner will begin receiving early warnings. Only then will the Product Owner be able to keep check of the pulse of the already shipped code and truly be responsible for any of their decisions that affect production. The Product Owner may not initially be convinced of the importance of early warnings that have no effect on real users. But sooner or later these early warnings will lead to production issues and the Product Owner will eventually learn to schedule all the necessary improvements reported by Developers on time. Such transparency really helps the Product Owner to make informed decisions and prioritize the Backlog better in order to avoid production issues.
No Handoffs
No Handoffs is one of the core practices at LiteOps. It’s also one of the main differences compared to DevOps and similar approaches where Ops perform production operations for outcomes produced by other roles. Such handoffs are the source of problems and frustration in engineering teams. One can even see an analogy in the financial world when someone takes a loan and someone else needs to pay it back. Obviously, this doesn’t work well.
It’s not that hard to implement a No Handoffs practice. Team members usually have a very clear understanding of what has been missed by other people in the team. For example, it’s a Developers responsibility to react and find a solution if they have made a change to the codebase that has led to a production application performance degrade. System Engineers will be notified by monitoring systems too, but it will be very clear for them that it’s something that Developers need to fix. At the time of development, the Developers probably haven’t noticed performance degrade, that’s why it has been pushed to production and only now has it become clear that a performance issue was introduced. Using other approaches such as DevOps, operations need to deal with such issues again and again. We think that there is a far better way to solve this. In such cases, Developers should proactively start resolving such issues because they are the ones who receive warnings about degraded system performance and they know what changes they implemented and deployed recently. If for some reason Developers do not start resolving such issues - Systems Engineers should tell Developers that their recent code changes and deployment have introduced a new issue.
If the same issues present themselves again and again it should be Systems Engineers that are then tasked with finding a solution, as Developers have shown that they are unable to do so. For example, automatically running performance tests on equivalent production datasets could help identify such performance issues before they reach production.
Balance
LiteOps is a developer-centric methodology. Developers commonly seek a mixture of change, stability and risk reduction. This means that no conflict arises among Systems Engineers who seek stability, Developers seek change and QA seeks risk reduction. All three main values are combined and balanced by a team of Developers with the help of other roles. Developers are free to make many decisions, but at the same time, it’s their job to measure risk. Why? Because if a wrong decision leads to production issues they will be the ones who need to handle the situation. So, instead of the classic battles waged between Developers who prefer the latest versions of dependencies and Systems Engineers who prefer older stable versions of dependencies, you get joint efforts where the whole team pulls together to identify which of the latest versions creates the lowest risk of an unwanted late-night call.
Over time Developers achieve the right balance of change, stability, and risk reduction, which in turn means that the project experiences a healthy amount of changes within acceptable levels of stability, and risk. This balance is spread to other roles too because the stability gains achieved by Developers decrease the demands on Systems Engineers to ensure stability. This naturally allows Systems Engineers and other roles to dedicate more valuable time to other values such as a change. So, the goal is to achieve a dynamic in which every role is united in its dedication to delivering change, stability and risk reduction.
On Call
Everyone in the team is on call. There is no rotation. The person who is related to the issue gets the call. If that person doesn’t pick up, then the next person who knows most about that issue gets the call. Everyone is fully responsible for their produced changes. This has real value for both the team and the process. Everyone starts to really care about their code and other changes that are produced. Everyone starts to really own their input and attach real importance to what will happen when changes are shipped to production. Major refactorings are not deployed on Friday afternoons. The risk is evaluated even for smaller changes. Systems Engineers get a call when there is an infrastructure issue or if Developers need help with an infrastructure related question. The beauty of this approach is that both Developers and Systems Engineers alike remain very motivated to avoiding any productions issues related to their work. What’s more, there is also a real effort made not to pass issues onto others, as no-one wants to be responsible for forcing others to clean up after them. Sooner or later your incident count drops to such unseen lows that no team member can remember when they last received a call.
Communication
It’s well known in the industry that lack of communication and cooperation between Developers and Systems Engineers is a common problem. Sometimes it’s so extreme that Developers begin to make infrastructure decisions without Systems Engineers, or System Engineers begin to make application decisions without Developers. There are various reasons for this. We find that Developers tend not to communicate with Systems Engineers because Developers are simply busy with new features that they need to ship. Moreover, Developers tend to work around and live with delivery pipeline issues instead of reporting them to Systems Engineers. Developers just try again if it’s a random issue. They will entirely ignore some glitch if it doesn’t completely prevent them from delivering features. Developers tend to ask for help only when the Delivery Pipeline is so broken that they can no longer ship features. Systems Engineers should continually check whether there are there signs of Delivery Pipeline problems or other infrastructure related issues. They should initiate discussions with Developers as soon as such signs are identified. It’s usually clear what needs to be improved after such discussions.
Developers should also initiate discussions with Systems Engineers more often. Such communication is initiated organically when a new feature requires some infrastructure change. But Developers should communicate with Systems Engineers on a much wider scope of topics. For example, instead of performing expensive code optimization, it’s possible to simply fine-tune the settings of infrastructure components and achieve a similar performance. There is nothing wrong with asking questions. Systems Engineers have less knowledge about applications and more knowledge about infrastructures. Developers have less knowledge about infrastructures and more about applications. So, it makes sense that these respective fields of knowledge should be shared.
Such communication ensures that all the roles contribute to important decisions. This reduces risks and costs in the long-term.
One Team
Our ratio of Systems Engineers and other roles to Developers is very low. Later stages projects usually have a rate of around 1:20 Systems Engineers to Developers. In most cases, it’s just a part-time Systems Engineer (the author of LiteOps). Usually, at the very beginning of a project, this rate is a bit higher. This high rate of Developers to other roles creates ideal conditions for the full integration of Systems Engineers and other roles into the Developers’ team. This allows software Developers to quickly ask questions and receive answers to how certain operation tasks can be completed more effectively, as well as information on how some infrastructure component actually function and so on. This strong and speedy line of communication encourages Developers to gain more knowledge about the environment they are building software for. Developers greatly benefit from quick communication with the other roles in the One Team process too. For example, spending a little time with a tester helps the Developer to quickly get to with where exactly the complex issue lays and what the best solution for the end user would be.
Working together with Developers, the Systems Engineers and other roles can develop a feeling for what is wrong. Judging by how often a Developer asks a certain question, the rest of the team will be able to build up a strong sense of where the potential issues lay. Developers have a habit of not offering exact fixes for situations, but through regular contact the Developer, the other team members can gain a better insight into what exactly should be improved.
Cycles
Developers deploy to production and other environments multiple times a day. This delivers numerous benefits as it encourages the habit of improving the deployment process and shipping small increments instead of big problematic updates. Deployment is fully automated, and any Developer can deploy with a single line command. Deployment should not take more than a few minutes. Developers don’t like to wait long for feedback. Frequent deployments will also encourage improvements to be made to the infrastructure. Developers will not deploy multiple times a day if deployment isn’t fast and smooth.
Everything you do should be cyclic too. Systems should be automatically checked against known vulnerabilities every day. Software process should be reviewed and improved every week. Every few weeks dependencies should be updated. Cycles everywhere. Cycles should be even more frequent if your project is processing efficiently. These cycles are the heartbeat of your project.
Reusability
We run a lot of projects at NECOLT and can’t reinvent the wheel for every new project. Instead, we craft reusable and stable infrastructures. Most of our projects share the same or very similar infrastructure setup, so Developers feel at home when moving from one project to another. This encourages Developers to solve production issues even on projects they have recently joined because they are already familiar with the infrastructure.
It’s essential to follow this rule every time. Even when we introduce new technologies in new or existing projects, at least some of infrastructure components are reused, which means that Developers are always familiar at least with part of the infrastructure.
One Pre-Production
We try to limit the number of pre-production environments as much as possible. The ideal case is one pre-production environment that is automatically deployed and used by the entire team, and represents the production environment as much as possible. Sometimes we need more than one environment to test some special cases, but even then, there is usually only one main pre-production environment that everyone uses. This approach solves a lot of issues. Using only one pre-production environment means that the entire team will be invested in making this environment the best that it can be. This leads to the best pre-production environment possible. Using only one pre-production environment would not be possible without a branching model that supports this approach. We created Git Double that supports it.
Upgrades
The “If it ain’t broke, don’t fix it” approach doesn’t quite work in the software world. Upgrading software is unavoidable, even if it is working perfectly now. Security upgrades are probably the fastest upgrade cycles available after actively developed application code. Such upgrades may sometimes even occur a few times a day. Sure, you can patch older versions and achieve a quick-win by avoiding software upgrades to latest versions, but sooner or later older releases stop getting patches and upgrading becomes even harder.
You might think that choosing not to upgrade dependencies is a good way to go. It works, so why upgrade? This is a very dangerous approach. Firstly, later versions tend to be better in many aspects compared to previous versions. Fewer bugs, better performance, better API and so on. This immediately helps you to produce better software. Moreover, building software on top of outdated APIs makes future upgrades harder. And every day this builds up more and more. Sooner or later the project turns into a big pile of legacy code that no one wants to work with. This becomes not only a code quality problem; but an even bigger hiring problem.
We try to find a good balance for upgrade cycles for each project. We usually try to upgrade dependencies at least once a month to the latest stable versions. We also try to automate patching against security vulnerabilities to at least once a day where it is possible (Automatic Security Updates is a good example). These practices help us to build an “up to date” mindset and fight against legacy code. Staying up to date is one of the most valuable investments a long-term project can have.
Systems Engineers ensure that infrastructure is up to date. Developers ensure that application dependencies are up to date. However, no matter what project stage you’re in, Developers are usually busy shipping new features and solving application issues in production. This means that they tend to postpone application dependencies upgrades, especially in bigger long-term projects. Meanwhile, Systems Engineers are usually not so busy, because commonly the infrastructure usually goes through far fewer changes than the application. This puts Systems Engineers in a very good position. They can proceed through infrastructure improvements and upgrades without rushing. They can also remind Developers to upgrade application dependencies if Developers don’t do this often enough. Other roles help Developers to stay up to date. For example, testers can help test applications after dependencies upgrades and find issues that automated tests can’t find.
Production Access
We try to ensure that we maintain the development environment as close to the production environment as we can. Some of our backend Developers even use the same operating system and packages as production servers. Clearly, however, they can’t be exactly the same in most cases. So, there are still some differences, and that’s usually why the code works on the Developer’s machine and not on the production. Commonly, a direct production or pre-production environment investigation will lead to faster results with fewer efforts. That’s why Developers have access to staging and production machines. All Developers receive unprivileged user access and Lead Developers receive privileged user access. An unprivileged user is allowed to deploy an application and perform other basic functions such as inspecting logs. A privileged user gains full access, but Lead Developers should use this very rarely. There should be no obstacles preventing Developers from investigating application issues in the production environment. Systems Engineers guarantee this.
Recoverability
Even the best software sometimes crashes. Recovery should happen automatically whenever possible. Automated recovery should be so smooth that users don’t notice it. Achieving this with part of the infrastructure components is possible. But still, some of these elements are considerably more complicated in terms of recovery. For example, when a bug in a database system has corrupted the database and this corruption has been replicated in secondary databases. Crashes sometimes occur which offer no possibility for automatic recovery, but generally, such instances are extremely rare in a well-designed and well-functioning infrastructure.
We track all infrastructure components with monitoring and recovery tools. These tools automatically recover crashed services whenever possible. Notifications are sent to both Systems Engineers and Developers whenever such crashes and recoveries happen. Both Developers and Systems Engineers investigate notifications and deliver a solution that will prevent such incidents in the future.
It’s not complicated to perform full disaster recovery for our projects because of their Simplicity. Our infrastructure is defined as a code and we try to remain as platform agnostic as possible. This means that it’s not even complicated to move from one platform provider to another. The code describing infrastructure, application code, data backups, and secrets is stored in multiple geographically distributed locations. All of this is enough to allow us to fully recover our production systems even if something happens to the platform where the systems run.
Monitoring
Monitoring for a running system is like automated testing for a software code. We cover running systems with monitoring as much as possible, just as we cover application code with automated tests as much as possible. Monitoring coverage is extended whenever the system experiences some issue that is not already covered by current monitoring.
The entire team receives monitoring alerts. This enables team members to figure out quickly which code change caused the issue. In most cases, rollback or code fix should solve such issues.
Early issue detection is the secret to a low production incident count. Our monitoring systems are tuned to detect issues early on, so the issues can be solved at business hours before they affect users in production. For example, tight performance monitoring allows you to identify scaling issues early. Early reports of slowdowns are investigated, and optimizations are implemented in business hours. This allows you to avoid scaling issues for regular growth projects until they start to cause problems for users in production. Also, this approach helps you to avoid having to work during non-business hours. Similar techniques are used for other types of monitoring.
Initially, some of the alerts are caused by infrastructure issues, especially if the infrastructure has new components for a particular project. Systems Engineers need to improve the infrastructure in order to avoid such alerts in the future. Such alerts should decrease over time to minimal accuracy. Eventually, only a small number of alerts should be caused by infrastructure issues. The majority of alerts should then be caused by the application, and those issues should be fixed by the application Developers with minimal, if any, Systems Engineer involvement.
It’s very important to eliminate false positive alerts. Developers start to ignore all alerts if false positive alerts reach them.
Short Leash
Most large-scale software projects have some complex technical challenges that require special attention during the entire software lifecycle. For example, some projects may tend to experience issues related to memory usage. Memory leaks and other memory usage issues are often time-consuming and expensive to resolve. A lot of teams only discover such issues when it’s too late; for example, when the application can no longer work because no memory is left on the server. At which point much effort is then expended into determining the root cause that was introduced a long time ago. This process is both very risky and inefficient. We solve such issues the other way around. We keep memory usage on a Short Leash by setting tight memory usage thresholds. Warnings are sent to the entire team when memory usage hits one of these tight thresholds. This usually helps us to figure out much faster what change was responsible for the higher memory usage or memory leak. This approach works for us very well and in most cases, significantly decreases risks and costs. This Short Leash approach is used to prevent other kinds of issues too.
No Overhead
We try to simplify everything and cut overheads wherever possible. For example, we try to avoid overheads associated with release management. The majority of our projects are long-term actively developed and continuously deployed projects. Such projects executed by other teams usually have complex release management procedures or even worse - dedicated release managers. Such extra efforts are costly, but more importantly, they deliver no benefits. Actually, the opposite is true - in our case they would complicate our regular releases multiple times a day. Not to mention the fact that complex release management eats up time that we could better dedicate to shipping features faster to the market. Instead, we use the lightweight Git branching model Git Double that allows us to ship QA approved increments multiple times each day, while avoiding the usual release management rigmarole.
Another example of how we cut our overheads is our applications architectures. We usually don’t use microservices architecture because this entails huge overheads. Instead, we use the macroservices architecture that is essentially a few well-designed monoliths. It’s way easier for Developers to develop, deploy and operate such systems. Infrastructure is also way simpler and that leads to less hassle for Systems Engineers. These are just a few of ways in which we cut overheads.
Multifunctional
We love technologies that do more than one thing and do it well. For example, PostgreSQL is not only a great relational database. Native JSON support also makes PostgreSQL a great document store. Instead of using a few different database systems we can usually do everything with a single PostgreSQL. Developers need to master one technology instead of many. This leads to the deeper knowledge of a particular technology. And this knowledge leads to fewer production issues. Also, it’s easier for Developers to better understand the environment and work with technology stacks containing fewer components.
Automation
Automation is one of the keys to the LiteOps methodology. Automation helps us to avoid human errors. Humans not only make mistakes, they also tend to forget things. For example, Developers might simply forget that something needs to be changed on the production servers when their new feature is deployed. The best way to avoid these pitfalls is to automate those production changes so Developers no longer have the opportunity to make mistakes by doing it manually on production. Also, Developers will not need to remember to perform those changes when the time comes. Generally, it’s best to assume that anyone can forget anything, and so you should automate it. How much should you automate? The rule of thumb is to automate as much as possible.
Not having to continually reinvent the wheel by automating as much as possible helps you to maintain a low rate of Systems Engineers to Developers. Tools such as Ansible and Chef have big communities with a wide range of open source cookbooks for most of the services we may need. By leveraging open source software, you can perform a lot of infrastructure automation with minimum drain on your Systems Engineer resources.
Deployment should be as simple as a short one-line command. This has numerous benefits. Risks of forgetting something during deployment or making mistake because everything is automated are minimal. Automated deployment is much faster than manual deployment, especially when it comes to more complex deployments. These benefits encourage Developers to deploy multiple times each day and achieve smooth small incremental system updates instead of large and troublesome deployments. Developers know applications best, that’s why they take care of deployment. They use such tools as Capistrano for automated deployment to servers and Fastlane for Android and iOS deployments. Both tools use expressive Ruby DSL and are easy to understand. Our Developers maintain these deployment configurations with the Systems Engineers help.
Scaling
Our experience helps us to predict what kind of growth a particular project should experience in the near future. For example, paid SaaS products usually experience regular growth. We also work on fast-growing projects. For example, we have built multiple social games backends for some of the top studios in the world. These games could hit millions of users on the first day. Scaling strategies are very different for these two types of projects.
We mainly rely on performance monitoring for regular growth projects. Load increases over time and Developers start to receive notifications when response times and other performance metrics hit their threshold. More often than not there is sufficient time to implement and deploy necessary optimizations after Developers have received such notifications. It’s a different situation entirely, however, when a code change introduces an instant performance decrease. Various techniques, such as testing new changes on a staging environment that is close enough to production (including dataset and other components) helps you to identify such issues early on. Generally, regular growth projects don’t require a lot of scaling planning. Usually simply reacting to early signs of slowdowns works well.
Scaling fast growing systems is a completely different story. There is simply not enough time to solve scaling issues after the system begins to experience higher loads and slowdowns. One technique we use is load simulation. We do load testing with common use case scenarios before a project launch and later major changes. Performance analysis tools are used during load testing. This helps us to identify which parts of the system are the slowest during load testing. The slowest parts are optimized first and optimization proceeds until the system can handle the planned load. The majority of scaling issues are eliminated before launch. Fast growing systems require much more upfront scaling efforts compared to regular growth systems.
These are just a few simplified examples of how we avoid scaling issues. Every situation is different, so we implement a custom strategy that works best for a particular project and adjust it as the project grows.
Security
100% security doesn’t exist. Security close to 100% requires a lot of work. We pick a strategy for every project individually as most of the projects are willing to invest differently in the security. For example, a public faced healthcare application will demand much higher security than to a social game.
Security is achieved through a combined team effort. Systems Engineers usually have a good security background and are generally well acquainted with security practices. For example, Systems Engineers usually know how to reduce attack surface and can apply this knowledge to the infrastructures they build. Other roles are usually not so experienced when it comes to security. We use multiple practices to solve this. We encourage Developers to analyze the list of security guides for the platforms they work with. Our Developers prefer to use mature and maintained frameworks and libraries that already have built-in security features and provide security updates. This helps us greatly to deal with common security issues such as SQL Injections or user input sanitization. We also use static analysis security vulnerability scanners such as Brakeman and Snyk that help us to locate some of the security issues. Code reviews help us to locate security issues that tools can’t. Automated patching is implemented whenever it is possible. Dependencies are scanned for vulnerabilities and updated often. Most of our projects have penetration testing which is done by external security companies. These are some of the techniques we use to maintain high-security standards for the projects we build.
Indicators
There are a number of indicators we often check so that we can get an idea of how well LiteOps is functioning for a particular project and team. You will see some of these listed below:
- Rare incidents - we usually have a very low rate of production incidents. This is mainly down to two reasons. Systems Engineers build infrastructure to such a level that it self-heals in most cases. Developers are responsible for the production issues caused by their code, so over time, they change their mindset and this helps reduce production issues to a minimum while still maintaining high productivity and frequent deployments.
- Frequent deployments - if Developers don’t deploy multiple times each day there must be an issue somewhere. The only case when it’s ok not to deploy often is when active project development has stopped and now requires only minimal maintenance.
- High rate of Developers to Systems Engineers (and other roles) - Systems Engineers should only be required to make minimal efforts after the initial stages of a regular growth project. That’s mainly because everything is already automated and easy to use for the Developers. The larger part of a Systems Engineer’s work should be dedicated to updating system stack and improvements, but the scope of this work should be negligible compared to how much effort the Developers puts into building the application.
- Up to date software - there is something wrong if a project doesn’t use the latest stable dependencies, even if it’s a large long-running project. There may be many reasons for why dependencies are not up to date, but each case needs to be investigated and root causes solved.
- Steady productivity - we track completed Story Points every Sprint. These numbers should be consistent over a longer period. If these numbers are not consistent, then the team should find the root cause and eliminate it.
- Team spirit - this methodology is very Developer centric. This means that all roles need to try and find ways in which they can help Developers to ship features every day. Developers appreciate this a lot and this appreciation trickles down to all the members in a dedicated team. This creates a very positive vibe for the team. If this vibe is lacking, then something needs to be changed.
LiteOps Coach
At least one person in the team needs to fully understand LiteOps inside out so that you can guarantee that the team follows the methodology every time. Without this person, you’ll never be able to follow every practice to the letter, meaning that you’ll never get the full LiteOps results. Systems Engineers are good candidates for the LiteOps Coach role as they usually tend to be good at seeing the big picture and understanding how the entire structure works.